

Predictive Modeling of Chronic Kidney Disease with Hypertension or Diabetes Based on Machine Learning Algorithms
-
摘要:
目的 构建社区高血压、糖尿病患者中慢性肾脏病(CKD)早期预测模型。 方法 群随机抽样昆明市4个城区的社区服务中心。对各中心建档居民分为疾病组(n = 1267)和对照组(n = 566),疾病组居民患有高血压和或糖尿病,对照组未患。分别调查2组CKD患病情况并进行问卷调查、实验室检查和人浆细胞瘤变异易位基因(PVT1)基因中5个单核苷酸多态位点等检测。Logistics回归筛选有统计学意义的危险因素纳入机器学习模型构建。算法模型包括支持向量机(SVM)、随机森林模型(RF),朴素贝叶斯(NB)模型和人工神经网络(ANN),并对比评价4个模型的效能和准确性进行比较分析。 结果 筛选出13项具有统计学意义的指标(P < 0.05),包括年龄、疾病类型、民族、血尿素氮、血肌酐、eGFR、PAM13量表分数、睡眠质量调查、熬夜情况、PVT1基因单核苷酸多态位点rs11993333及rs2720659。基于危险指标建立机器学习算法模型。ANN模型的准确度达94.6%、特异性为66.67%、Kappa值为0.7294、ROC和PRC曲线下面积(0.9418和0.9261)均高于其它3种模型;RF模型敏感性最高位100%。 结论 机器学习算法构建的CKD早期诊断模型在社区高血压或糖尿病患者中有较好的预测效能。尤其ANN模型各项性能优于其它。 Abstract:Objective To build the early predictive model for chronic kidney disease (CKD) in hypertension and diabetes patients in the community. Methods The CKD patients were recruited from 4 health care centers in 4 urban areas in Kunming. The control group was residents without hypertension and diabetes (n = 1267). The disease group was residents with hypertension and/or diabetes (n = 566). The questionnaire survey, physical examination, laboratory testing, and 5 SNPs gene types in the PVT1 gene. The risk factors, which were filtered with logistics regression, were used to build predictive models. Four machine learning algorithms were built: support vector machine (SVM), random forest (RF), Naïve Bayes (NB), and artificial neural network (ANN) models. Results Thirteen indicators included in the final diagnostic model: age, disease type, ethnicity, blood urea nitrogen, creatinine, eGFR from MDRD, ACR, eGFR from EPI2009, PAM13 score, sleep quality survey, staying-up late, PVT1 SNP rs11993333 and rs2720659. The accuracy, specificity, Kappa value, AUC of ROC, and PRC of ANN are greater than those of the other 3 models. The sensitivity of RF is the highest among 4 types of machine learning. Conclusions The ANN predictive model has a good ability of efficiency and classification to predict CKD with hypertension and/or diabetes patients in the community. -
Key words:
- Chronic kidney disease /
- Machine learning /
- Predictive modeling /
- Hypertension /
- Diabetes
-
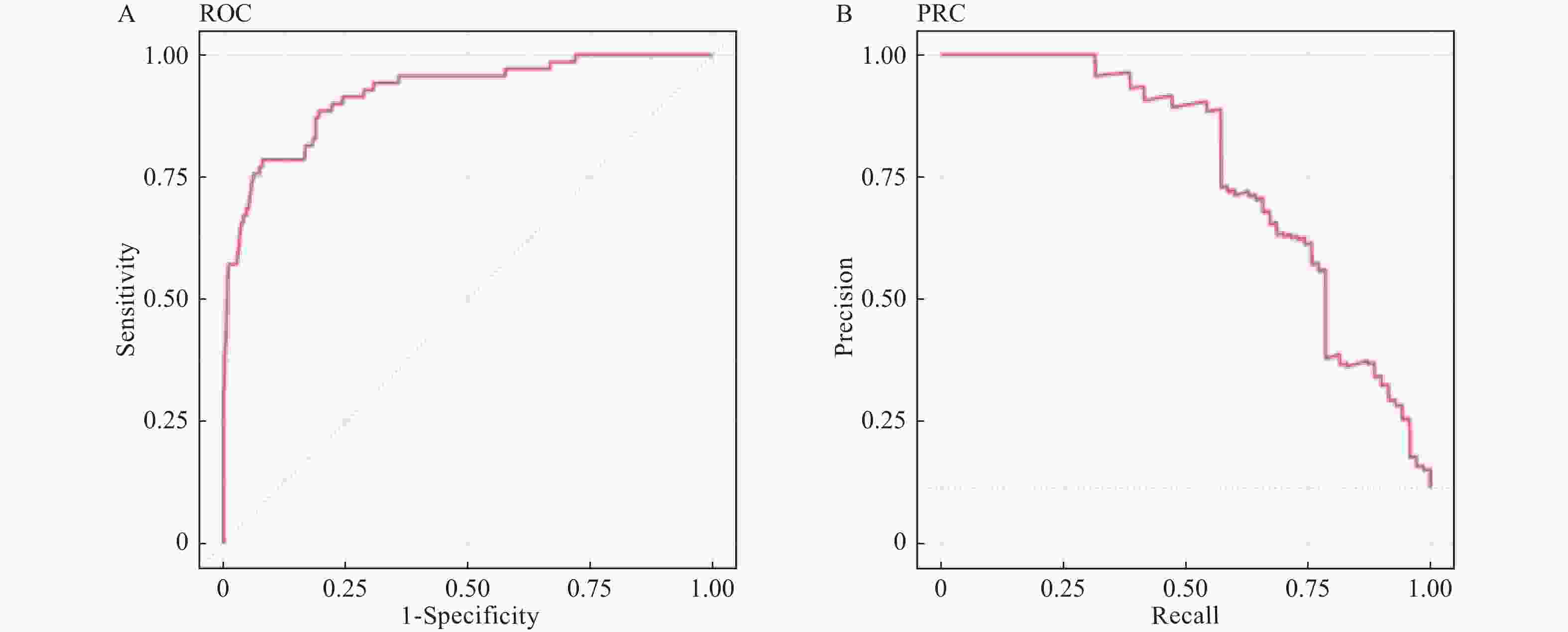
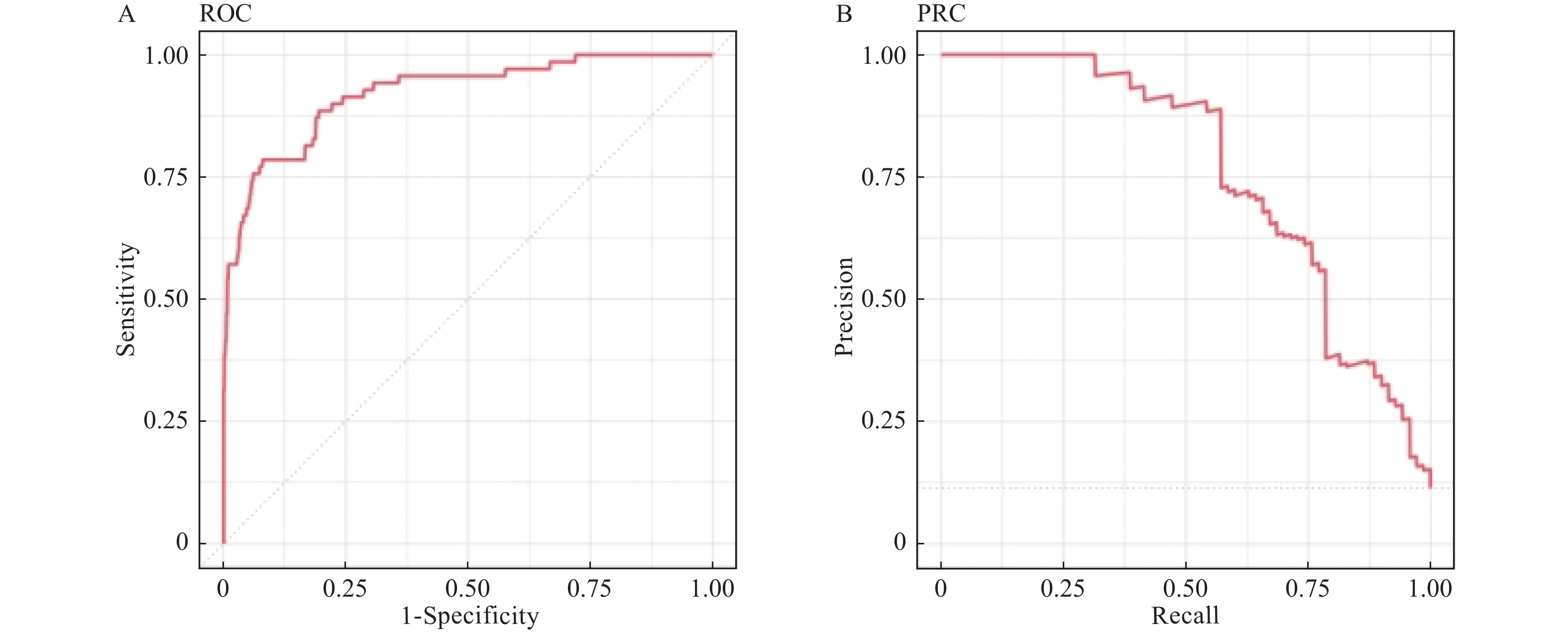
图 3 支持向量机模型ROC和PRC的AUC
A:支持向量机模型ROC;B:支持向量机模型的PRC。
Figure 3. AUC of ROC and PRC in Support Vector Machine (SVM)
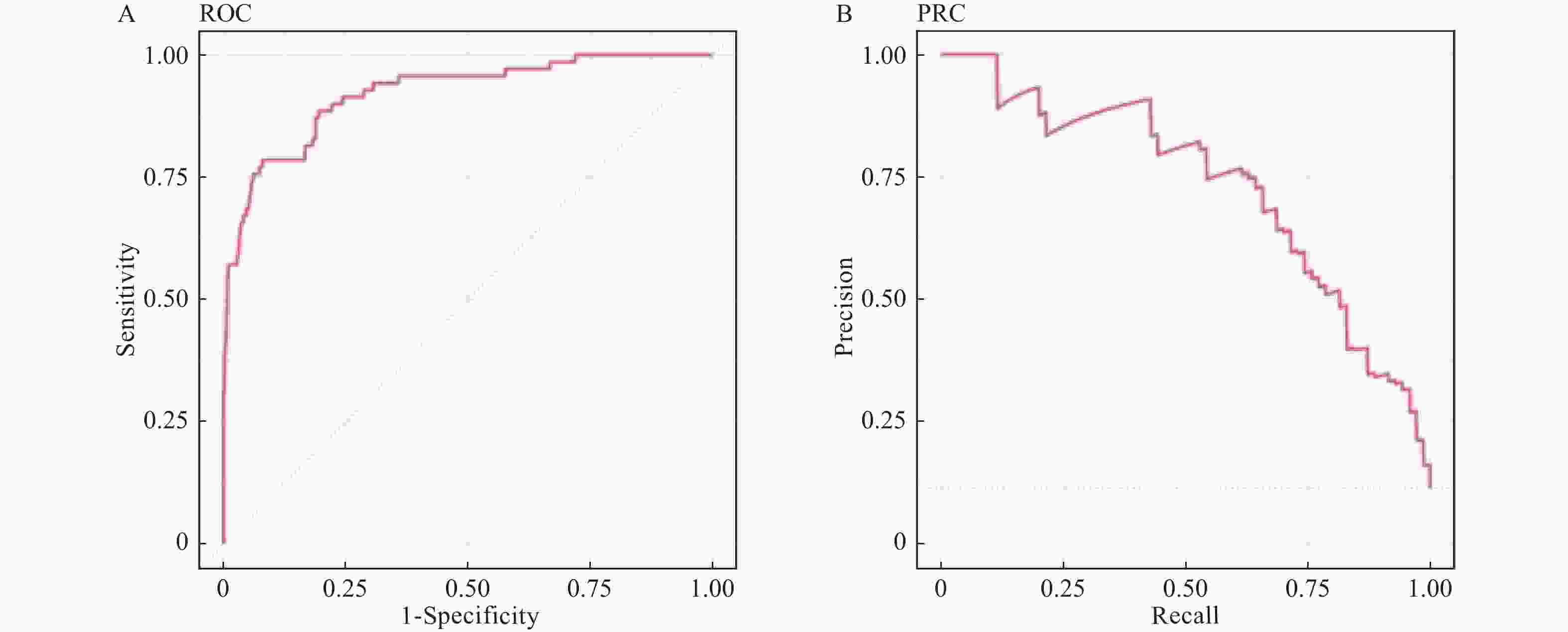
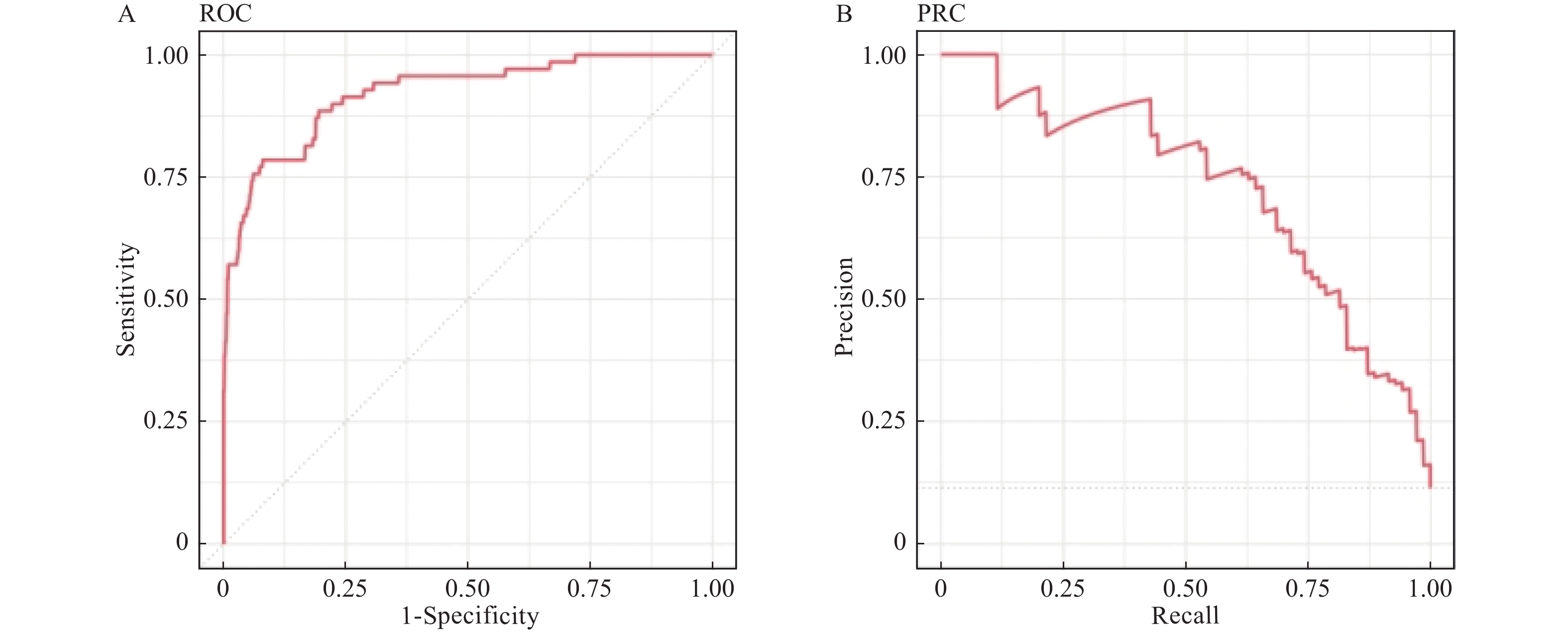
图 4 自由森林模型ROC和PRC的AUC
A:自由森林模型ROC;B:自由森林的PRC。
Figure 4. AUC of ROC and PRC in Random Forest (RF)
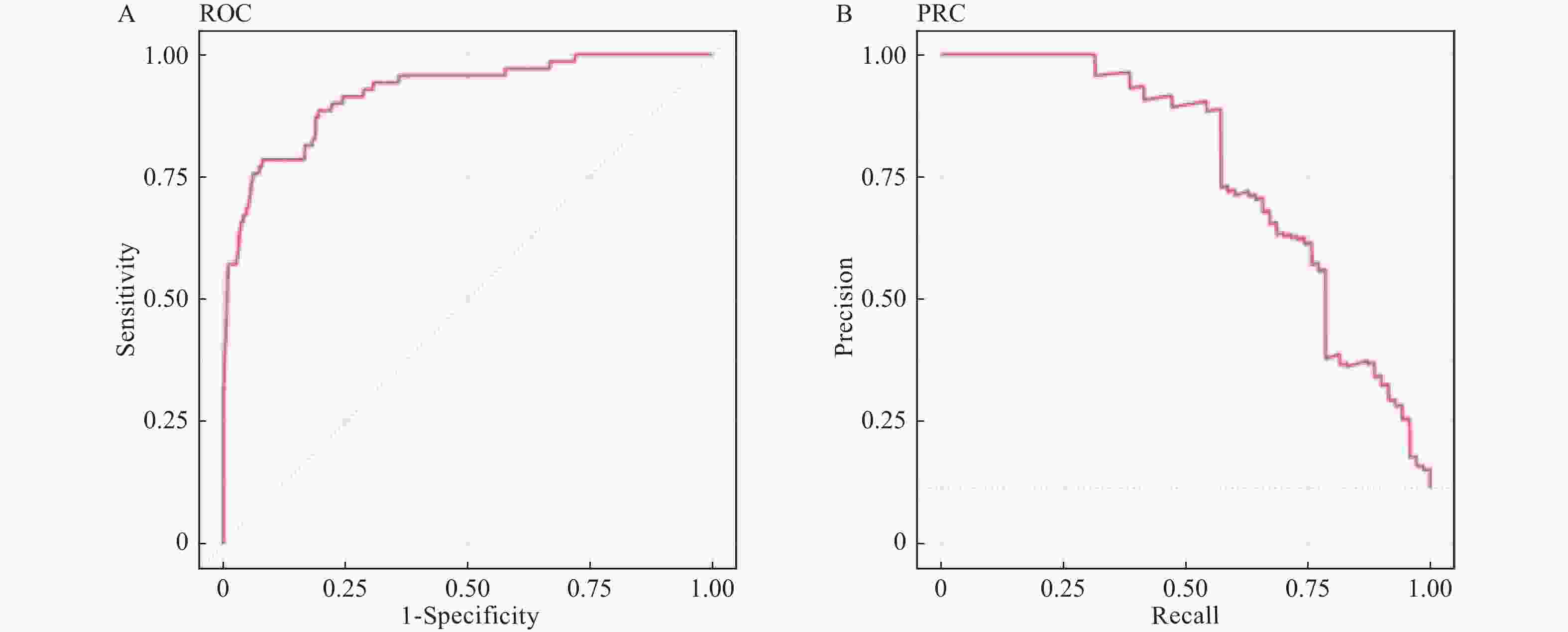
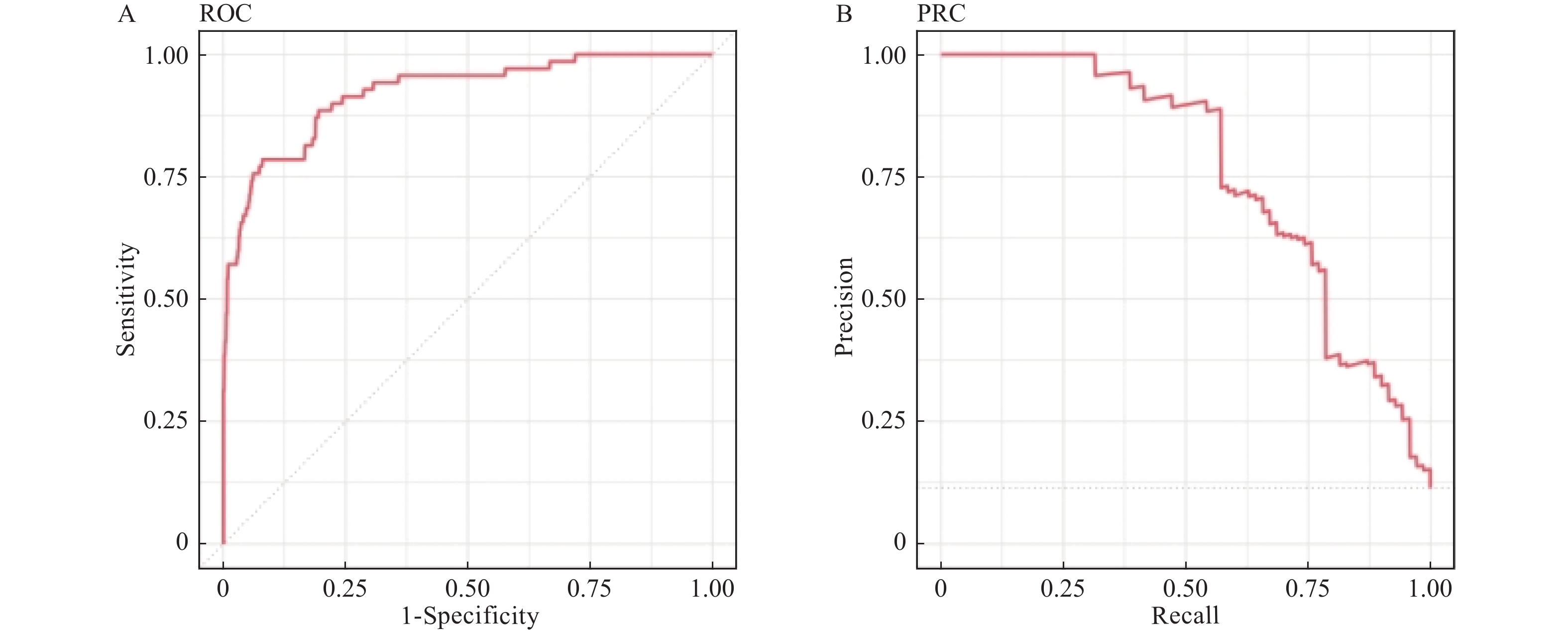
图 5 朴素贝叶斯模型ROC和PRC的AUC
A:朴素贝叶斯模型ROC;B:朴素贝叶斯模型的PRC。
Figure 5. AUC of ROC and PRC in Naïve Bayes (NB)
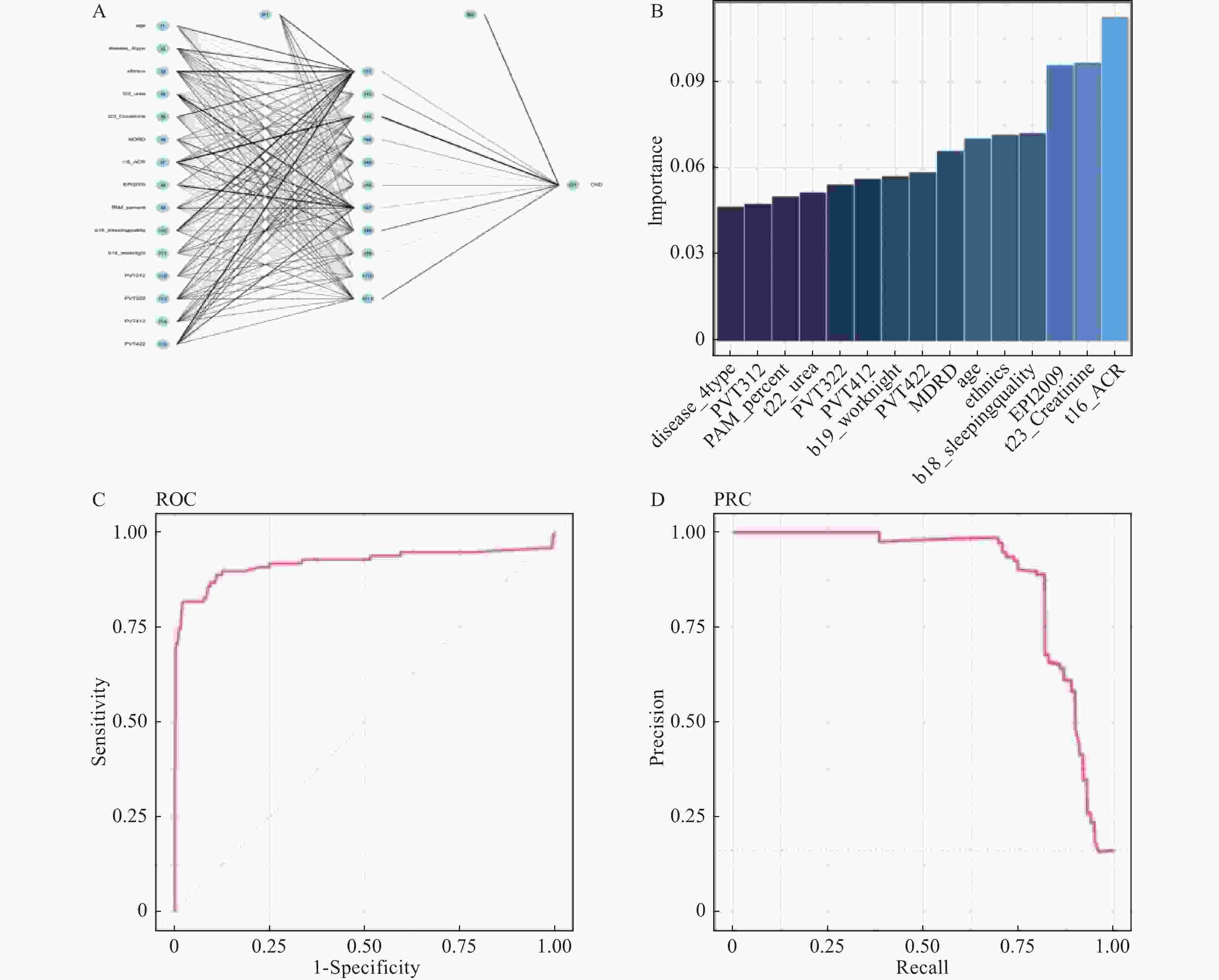
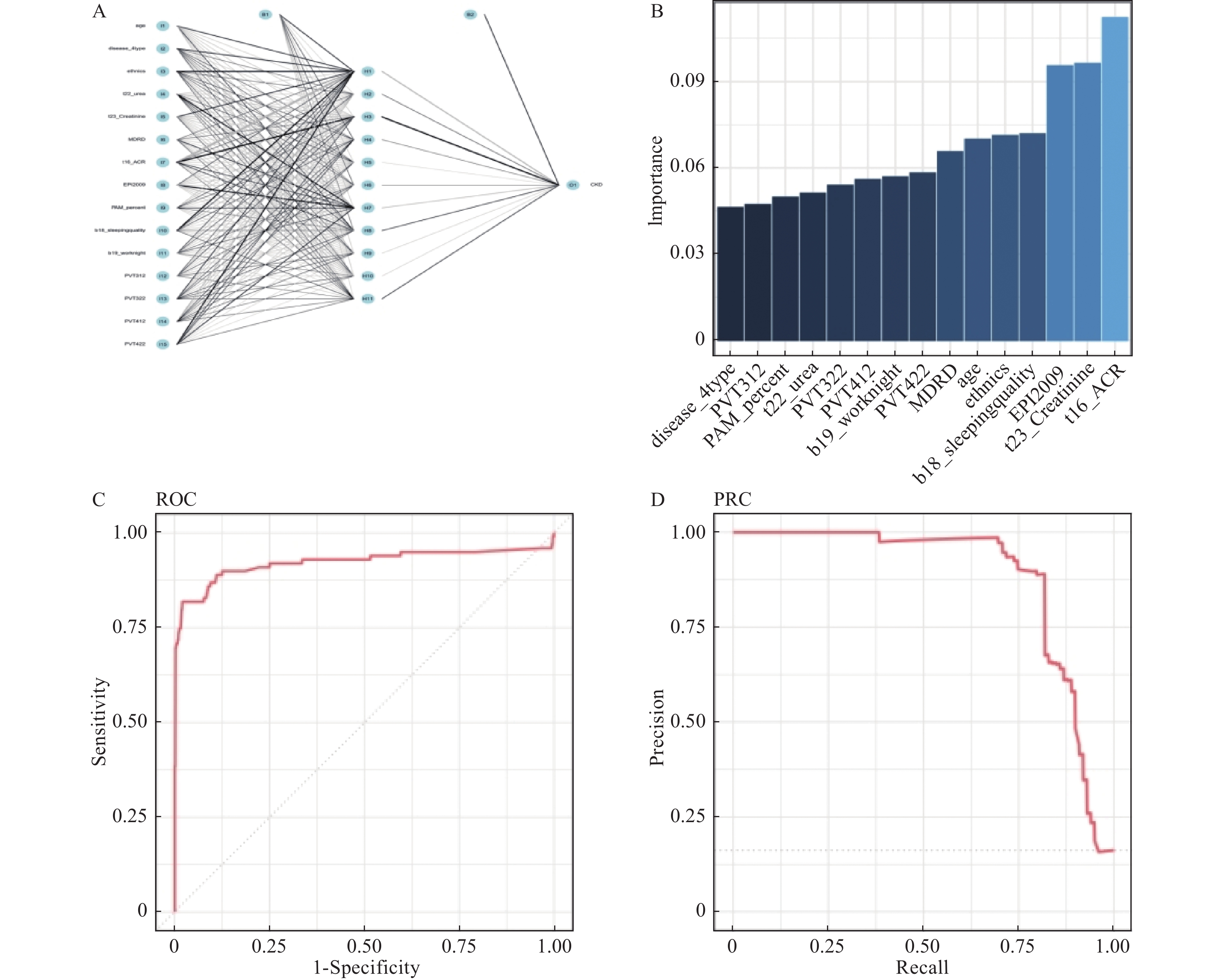
图 6 人工神经网络评价
A:人工神经网络模型各层图,I代表输入层,H代表隐藏层,O代表输出层,B代表偏倚矫正神经节点;B:ANN模型各指标重要性评价;C:人工神经网络模型的ROC;D:人工神经网络模型的PRC。
Figure 6. Evaluation for artificial neuron net (ANN)
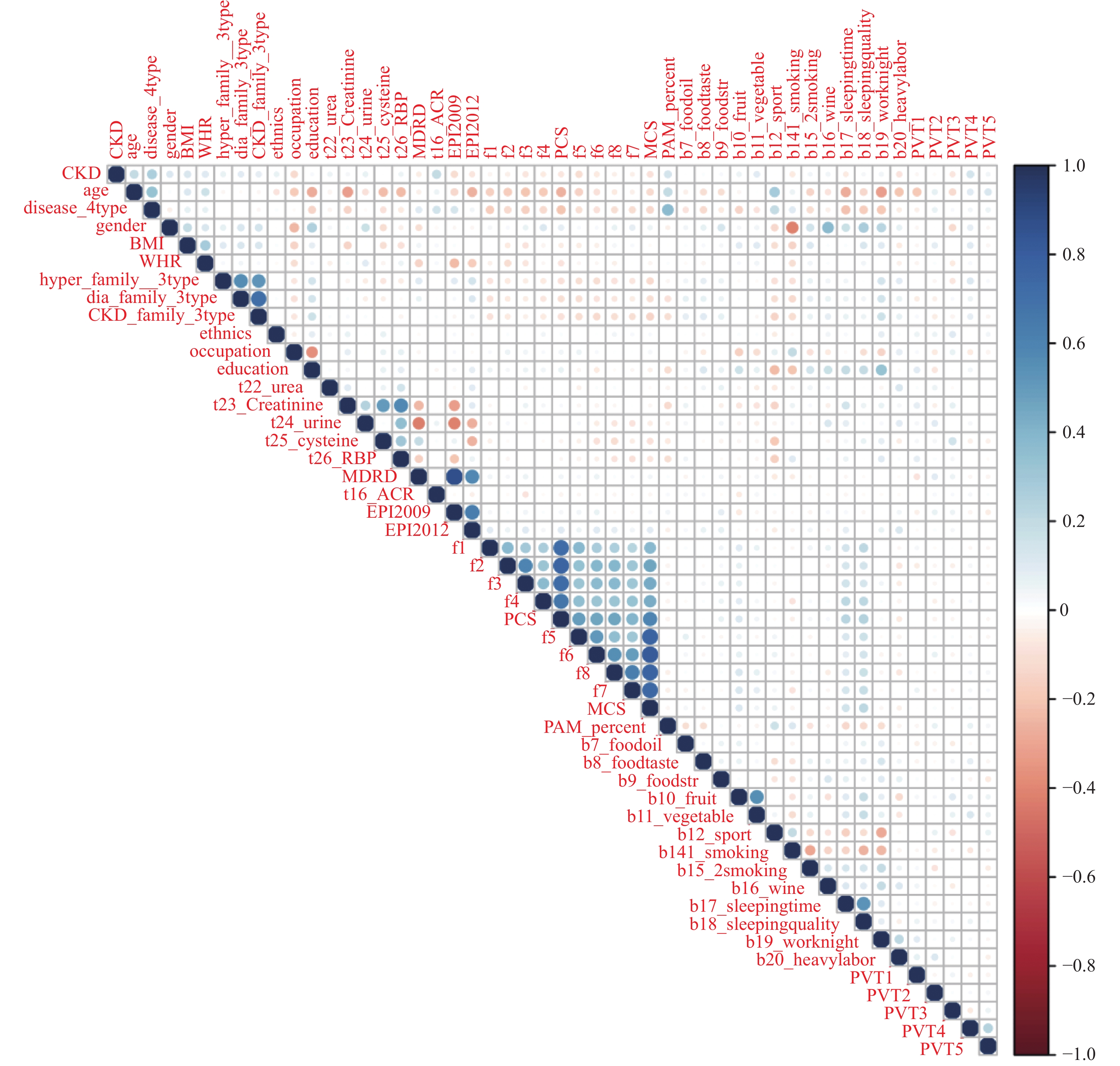
表 1 研究对象分组数据分析[n(%)]
Table 1. Base line data analysis between control group and disease group[n(%)]
组别 n non-CKD CKD χ2 P 对照组 1267 1171(92.43) 96(7.58) 疾病组 高血压 344 258(75.00) 86(25.00) 糖尿病 96 68 (70.83) 28 (29.17) 149.64 < 0.0001* 高血压合并糖尿病 126 80(63.49) 46(36.51) *P < 0.05。  下载: 导出CSV
下载: 导出CSV
-
[1] 陈婷,邓云蕾,龚蓉. 终末期肾病合并感染的生物标志物检测意义及研究进展[J]. 临床肾脏病杂志,2022,22(3):243-247. [2] Santos M,Yin H,Steffick D,et al. Predictors of kidney function recovery among incident ESRD patients[J]. BMC Nephrol,2021,22(1):142-153. doi: 10.1186/s12882-021-02345-7 [3] Bikbov B,Purcell C,Levey A,et al. Global,regional,and national burden of chronic kidney disease,1990-2017: A systematic analysis for the Global Burden of Disease Study 2017[J]. Lancet (London,England),2020,395(10225):709-733. doi: 10.1016/S0140-6736(20)30045-3 [4] 王仕鸿,令垚,杨子华,等. 基于时间序列模型的中国2020—2029年慢性肾病发病和患病情况预测研究[J]. 中国慢性病预防与控制,2023,31(11):801-806. [5] Zhang L,Wang F,Wang L,et al. Prevalence of chronic kidney disease in China: A cross-sectional survey[J]. Lancet (London,England),2012,379(9818):815-822. doi: 10.1016/S0140-6736(12)60033-6 [6] 郑旭彤,张曼,秦朱珠,等. 慢性肾病患者肾脏替代治疗辅助决策工具开发与验证研究的范围综述[J]. 中华护理教育,2023,20(4):500-507. doi: 10.3761/j.issn.1672-9234.2023.04.021 [7] 高翔,梅长林. 慢性肾脏病筛查诊断及防治指南[J]. 中国实用内科杂志,2017,37(1):28-34. [8] Zeng H,Jiang R,Zhou M,et al. Measuring patient activation in Chinese patients with hypertension and/or diabetes: Reliability and validity of the PAM13[J]. J Int Med Res,2019,47(12):5967-5976. doi: 10.1177/0300060519868327 [9] Chen T,Li X,Li Y,et al. Prediction and risk stratification of kidney outcomes in IgA nephropathy[J]. Am J Kidney Dis,2019,74(3):300-309. doi: 10.1053/j.ajkd.2019.02.016 [10] Chen Z,Zhang X,Zhang Z. Clinical risk assessment of patients with chronic kidney disease by using clinical data and multivariate models[J]. Int Urol Nephrol,2016,48(12):2069-2675. doi: 10.1007/s11255-016-1346-4 [11] Polat H,Danaei Mehr H,Cetin A. Diagnosis of chronic kidney disease based on support vector machine by feature selection methods[J]. J Med Syst,2017,41(4):55-66. doi: 10.1007/s10916-017-0703-x [12] Almansour A,Syed F,Khayat R,et al. Neural network and support vector machine for the prediction of chronic kidney disease: A comparative study[J]. Comput Biol Med,2019,109(6):101-111. [13] Wolfgram F,Garcia K,Evans G,et al. Association of albuminuria and estimated glomerular filtration rate with functional performance measures in older adults with chronic kidney disease[J]. Am J Nephrol,2017,45(2):172-179. doi: 10.1159/000455388 [14] Zhang L,Zuo L,Xu G,et al. Community-based screening for chronic kidney disease among populations older than 40 years in Beijing[J]. Nephrology,dialysis,transplantation:official publication of the European Dialysis and Transplant Association - European Renal Association,2007,22(4):1093-1099. doi: 10.1093/ndt/gfl763 [15] Wouters J,O'donoghue J,Ritchie J,et al. Early chronic kidney disease: Diagnosis,management and models of care[J]. Nature Reviews Nephrology,2015,11(8):491-502. doi: 10.1038/nrneph.2015.85 -
 点击查看大图
点击查看大图
计量
- 文章访问数: 2180
- HTML全文浏览量: 999
- PDF下载量: 45
- 被引次数: 0
